Sci-Phi3: An LLM companion for STEM students
Key Takeaways
This project was part of the Modern Natural Language (CS-552) class directed by the professor Antoine Bosselut. This project was definitely a challenge from which I've learned many important things.
We evaluated Sci-Phi 3's performance throughout different stages of training, focusing on the quality of its explanations and its accuracy in answering multiple-choice questions.
Using SFT and DPO training, we observed small improvements in the model's ability to explain its answers. It achieved higher BERTscores, and the DPO preference score improved, aligning more closely with human preferences.
However, the model's accuracy on multiple-choice questions dropped significantly compared to the base model, especially when we introduced retrieval-augmented generation (RAG). This likely introduced irrelevant information that negatively impacted performance.
The final results may be due to knowledge loss from extensive training, as well as the dataset choice. For the final evaluation, we used ScienceQA, which includes simpler questions, some of which are non-academic. This, combined with training on academic data, could have contributed to the decline in performance. Additionally, RAG had much room for improvement and often retrieved irrelevant text unrelated to the questions.
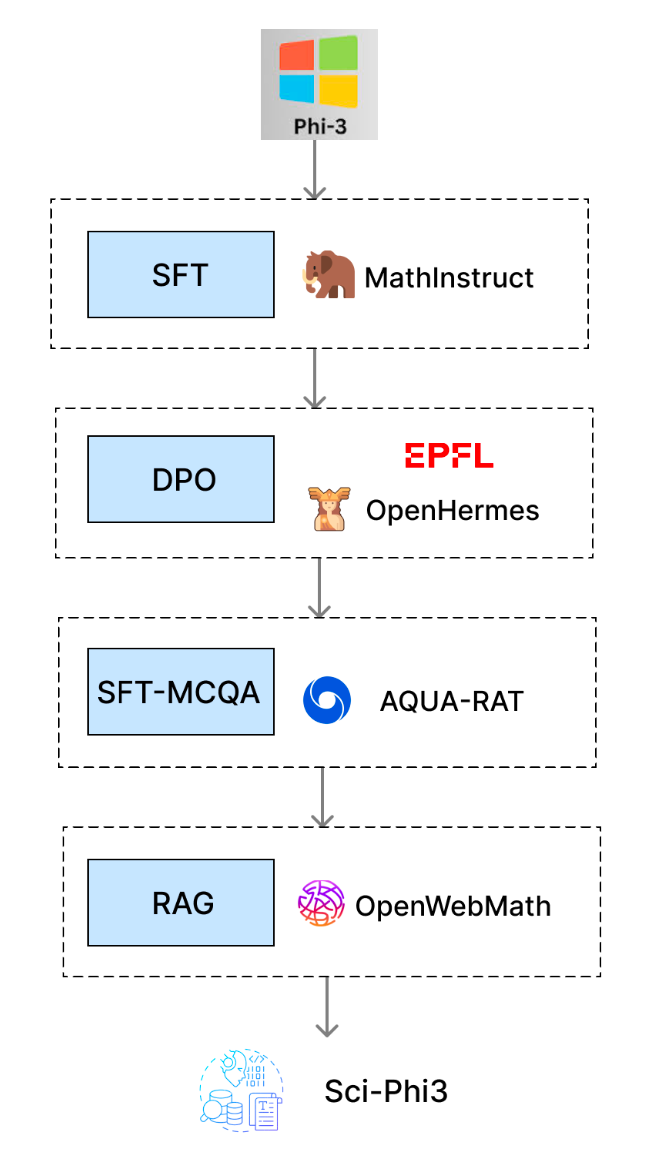
The task was to develop a model capable of answering MCQs from various bachelor courses at EPFL, ranging from Analysis I to Aerospace Physics. Here are three key things I’ve learned:
Potential Improvements in Evaluation We evaluated the model before MCQA training using a subset of the MATH benchmark, measuring answer quality with BERTscore and using the DPO win rate to check if the model increasingly preferred the correct answers.
For the final evaluation, we tested the trained models on ScienceQA, as it is a widely used benchmark.
However, due to the significant difference in training data, our fine-tuned model performed worse than the base model. Fine-tuning can lead to knowledge forgetting and over-specialization to a specific domain or task.
RAG needs to add relevant information, otherwise, it can confuse the model even more, especially smaller models like Phi-3. These smaller models are more affected by irrelevant text in their context compared to larger models. The key solution is to build an effective retrieval system and trim documents down to only the most relevant ones for the task.
In our case, the documents were from ArXiv or a subset of a web-based dataset (OpenWebMath), but they were not relevant to our evaluation or academic task. In hindsight, I would have selected a subset of Wikipedia or found well-summarized articles on bachelor-level scientific topics.
The EPFL dataset consisted of over 100 student annotations made with GPT-3.5 on Bachelor and Master STEM quizzes. Given that GPT-3.5 struggles with accuracy in many questions (with a MATH benchmark score of 43.1 compared to GPT-4 Turbo's 87.9), it's likely that many labels and answers were incorrect. Additionally, students used different prompt engineering techniques, further complicating the consistency and quality of the data, with varying formats and Chain of Thought approaches.
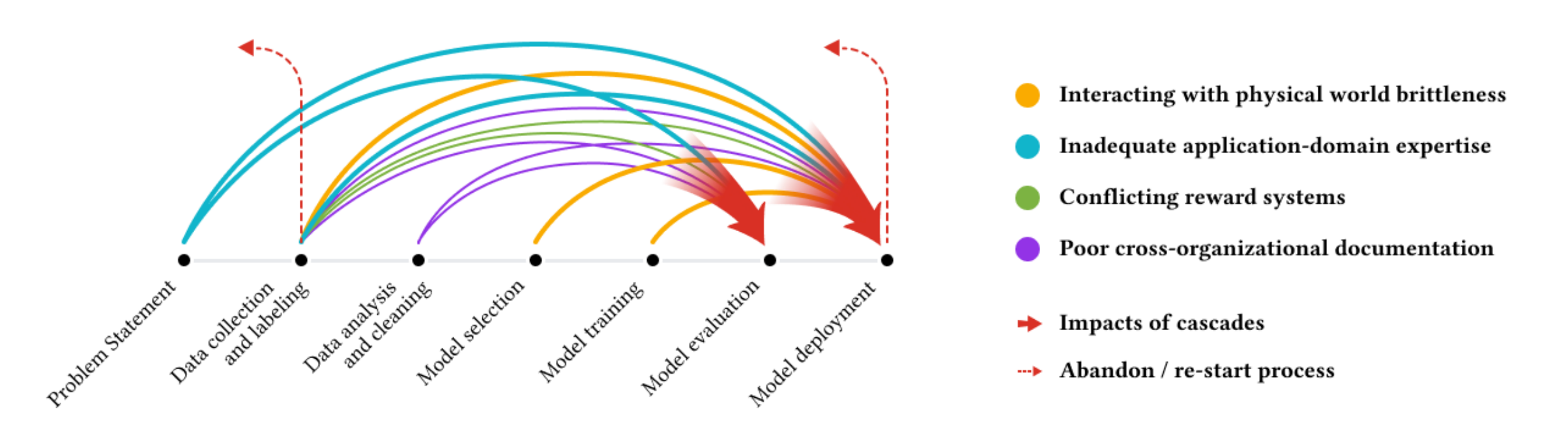
Data mistakes on every step affect the final performance in a downstream task of the model
As like a cascade, problems and errors in the data will lead to poor performances. We fine-tuned our model on a highly diverse and likely flawed dataset, which resulted in disappointing outcomes — garbage in, garbage out.
Finally, combining this with the previously mentioned silly mistakes, we ended up with a situation that caused the model to "de-learn," unfortunately.
Even though the performance didn't meet our expectations, my team and I learned a lot throughout the process. Looking back, we also made some great decisions.
One key choice was to prioritize running numerous experiments from the start. We trained over 8 adapters, experimenting with different combinations of SFT and DPO training, various hyperparameters, and datasets.
Additionally, we effectively evaluated our intermediate steps before applying RAG, using both BERTscore and the DPO performance score to assess progress.
And in the end, we still received a good grade! :)
Team: Davide Romano, Ke Li, Kaede Johnson
Author: Davide Romano