Voices of the Manhattan Project
Key Takeaways
This project was done for the course History and the Digital of the professor Jerome Baudry.
"Communicative memory" is people's everyday tales and talks about an event. It's messy, partial, changeable, impacted by psychology and society. It lasts as long as those who witnessed the event live, about 80-100 years. Given we're in the 2020s, we're nearing this limit for MP events, mostly from 1941-1945.
"Cultural memory" covers concrete aspects of a society's culture like texts, rituals, art, and monuments. These are made on purpose to remember and bring back important past events shared by all.
These two terms coined by Assmann in his work on oral memory and history.
Based on Assmann theories, we defined our two main research questions as:
1 - What topics and individuals are retained in the communicative memories of the AHF oral histories?
2 - How are these topics and individuals related to each other within the context of the AHF oral histories?
To comprehend better the context of our study we read various sources about:
1 - Assmann’s work on communicative/cultural memory
2 - Explored the concept of "conversational remembering" and the factors that shape the dynamics of recalling events.
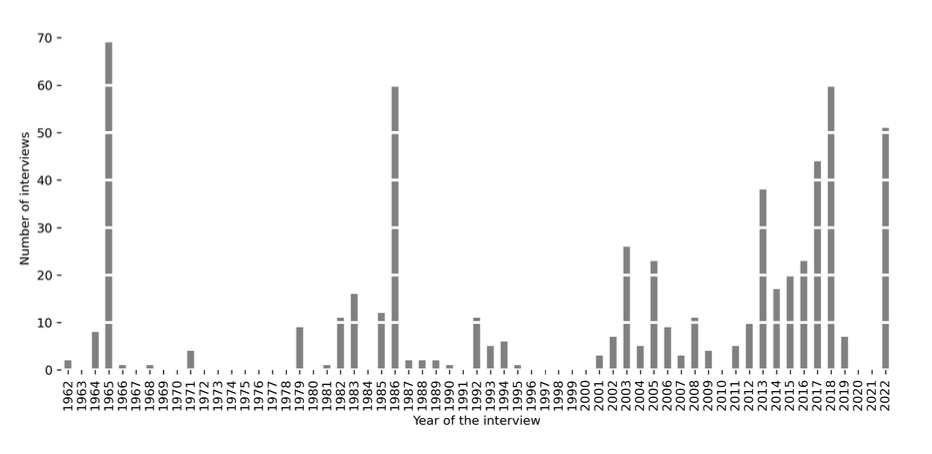
Our research analyzes 600 interview transcripts from the Voices of the Manhattan Project, managed by the AHF and Los Alamos Historical Society.
Despite the rich data, the limited sample from over 150,000 workers may not fully represent diversity, and the reliance on memories from over 60 years ago introduces potential biases. Additionally, the AHF's emphasis on personal stories could skew the cultural context of the interviews.
The data was scraped from the web, then we utilize a basic NLP pipeline for text pre-processing.
Topic modelling: We applied Latent Dirichlet Allocation (LDA) using the Gensim library.
Person Entity Extraction: we utilize SpaCy for Named Entity Recognition (NER) to detect individuals mentioned in the interviews.
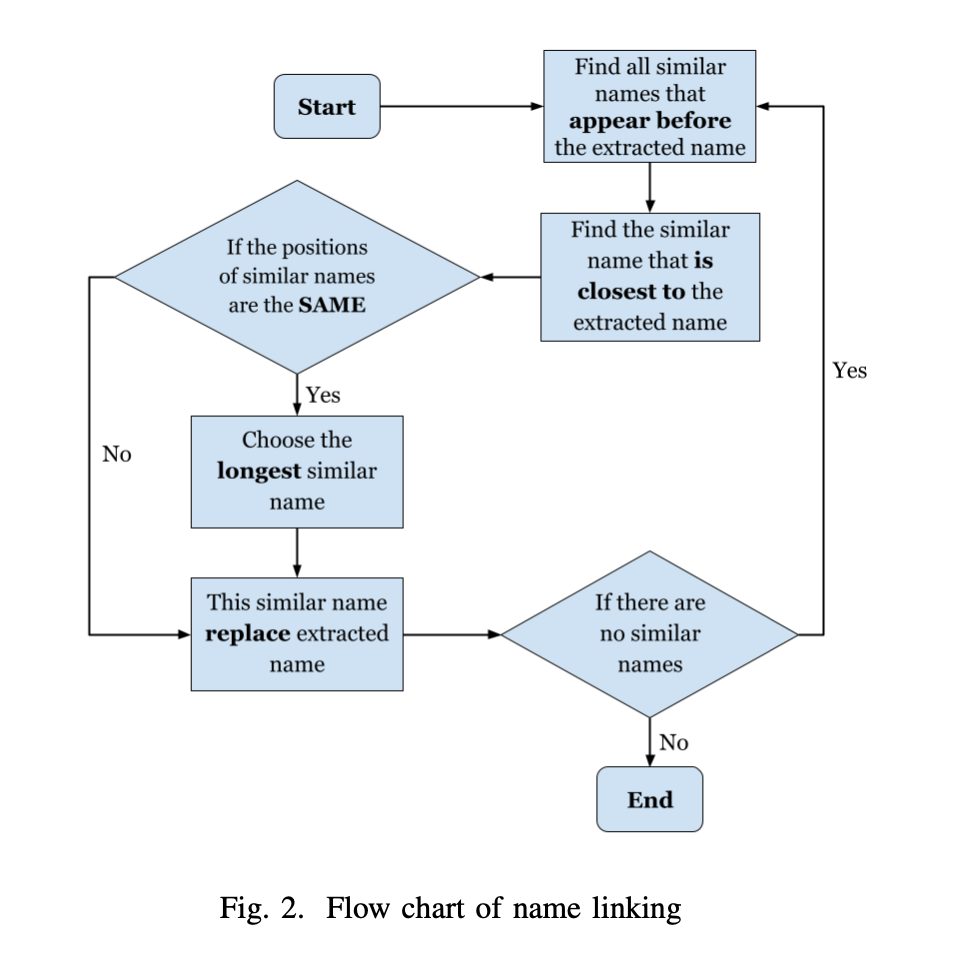
We tested various techniques to solve the problem of entity disambiguation including methods like Soundex and string matching followed by the name linking pipeline described here:
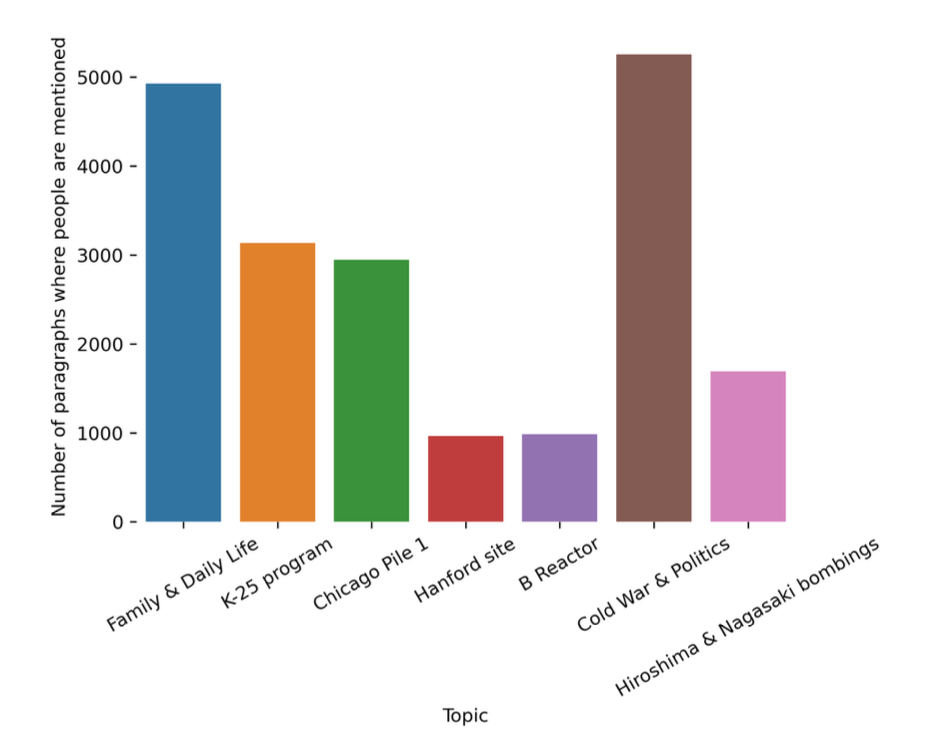
We identified 7 main topics that not only include scientific and technical aspects, but also valuable insights into the interviewees’ daily lives, familial experiences, and the political context of this event.
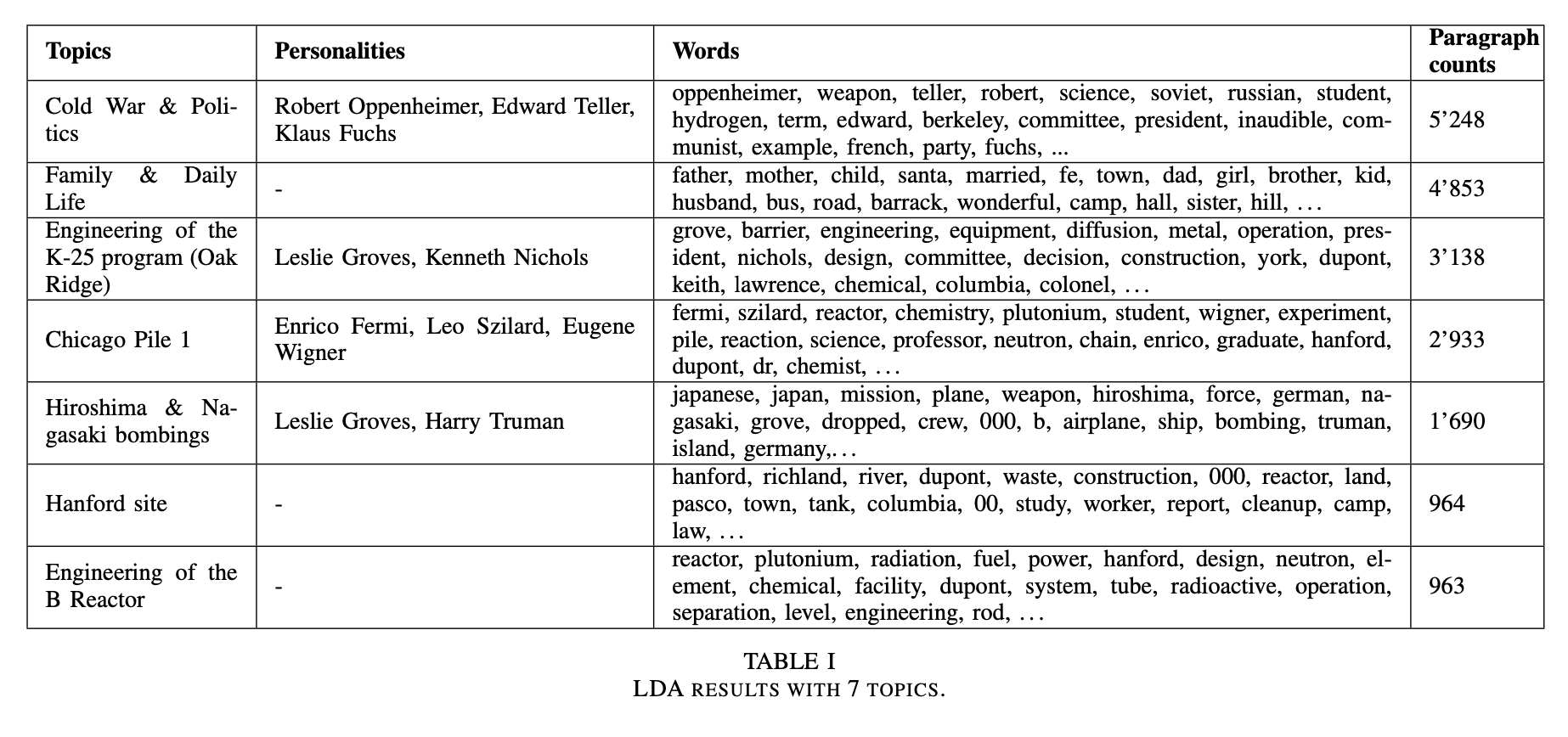
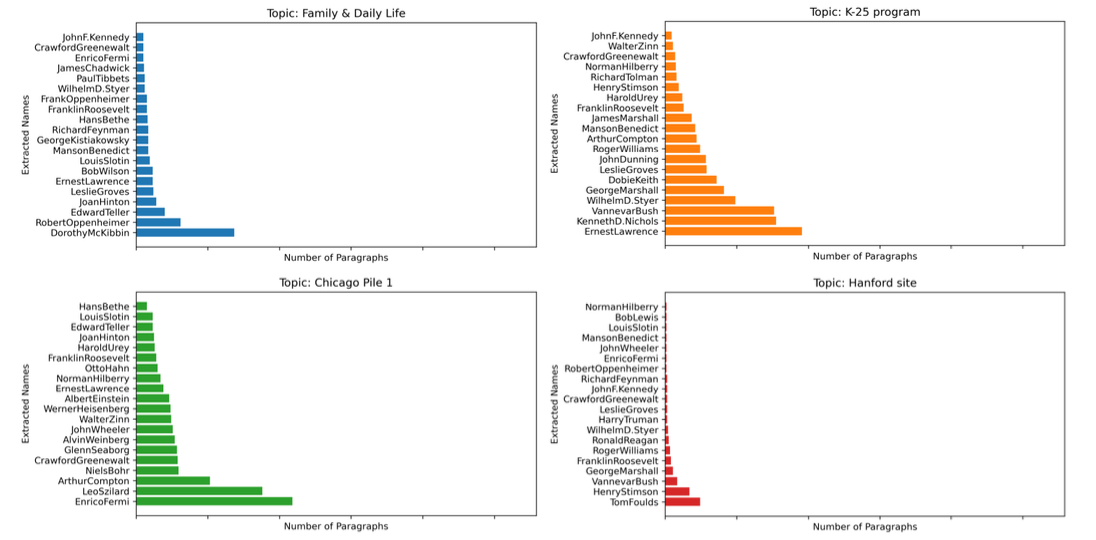
The most notable figures were some well-known figures like Robert Oppenheimer, Leslie Groves, Enrico Fermi and Edward Teller.
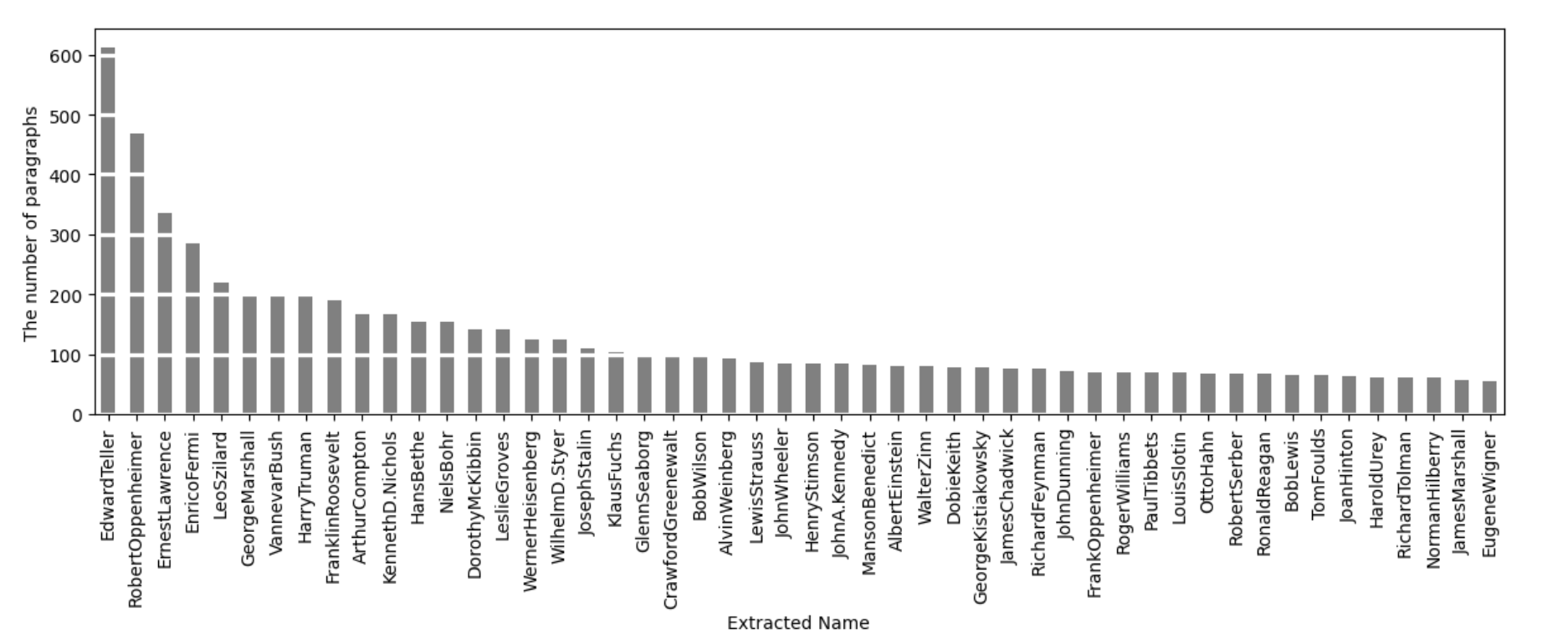
32% of mentions belong to only 1% (50 names) of the recognized total. One possible hypothesis is related to the constraints of conversational remembering. As time passes, famous individuals often receive more comments and questions from interviewees, thus keeping these people in the collective memory even more.
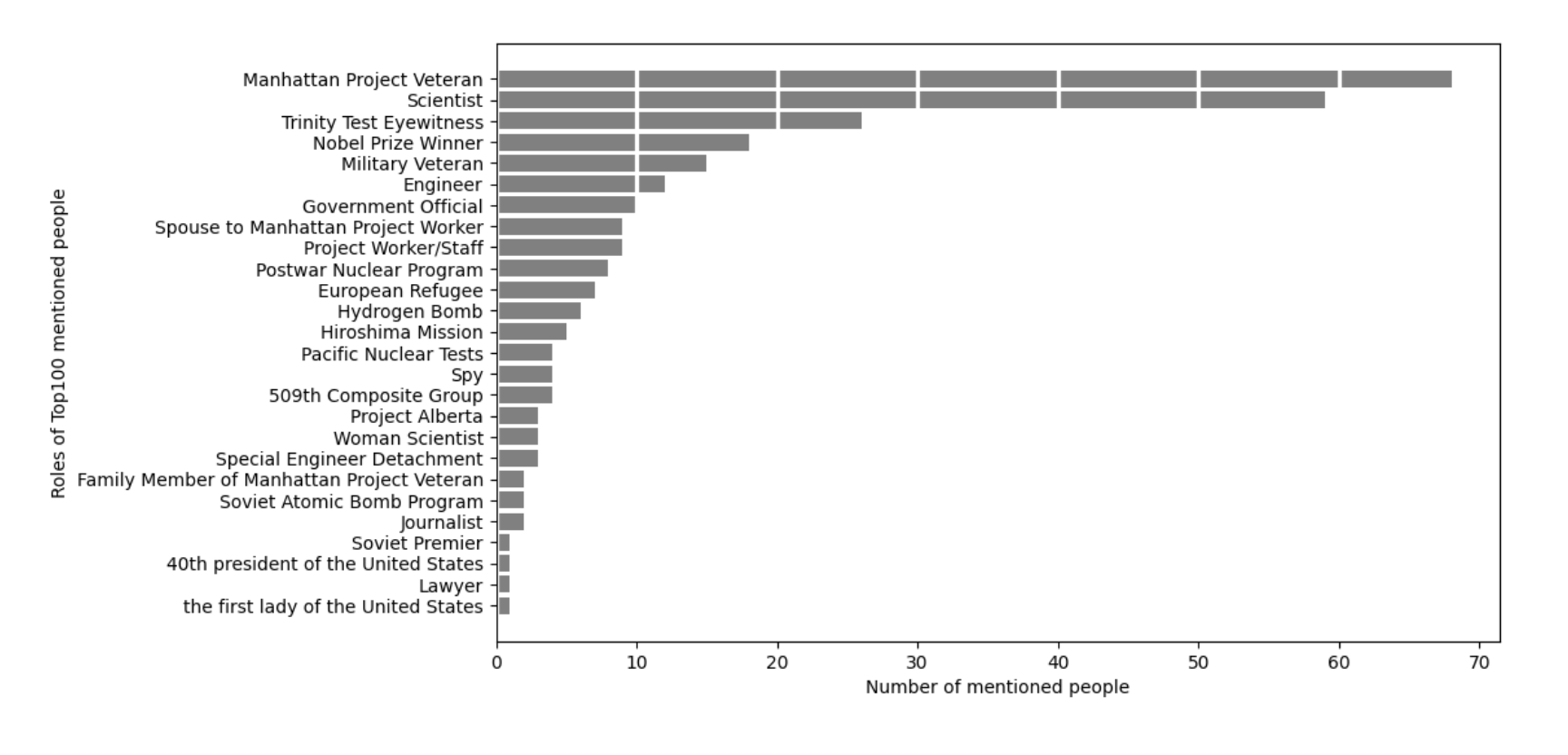
In the top 100 individuals mentioned in the interviews we also noted the presence of some interesting exceptions, such as military veterans, a dozen Project workers/staff, and a few women scientists.
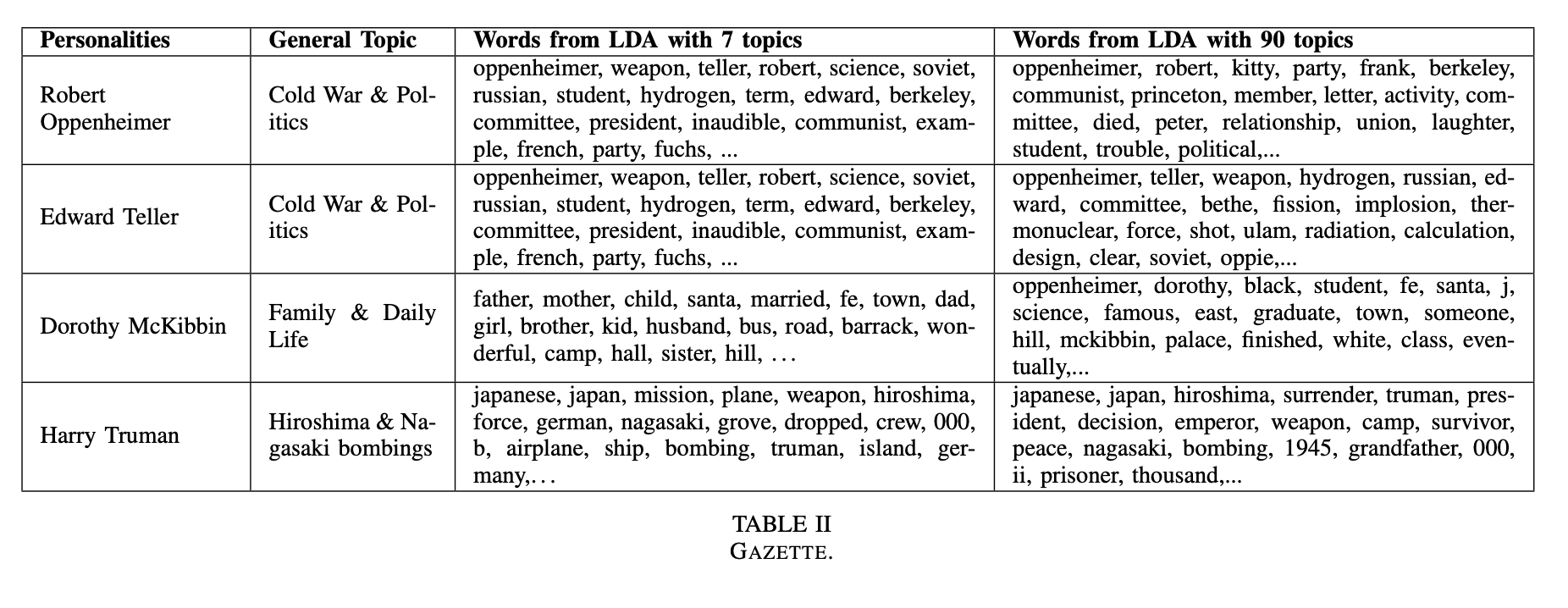
Finally, we also created a ”gazette” in Table II that associates for each person a topic and a list of words.
(Historical) research is hard: I discovered how rigourous one has to be before concluding anything.
Let the dataset speak: It's tempting to focus on methods and algorithms, hoping they align perfectly, but in reality, this works out only 1% of the time.
During our project's evolution, we had to discard code and results as they didn't consider crucial assumptions or tried to address unanswerable or historically obvious questions.
We had to ask ourselves: what questions is worth answering with this dataset?
Read, read, read: with my background of computer science, I entered a new realm of humanities and historical research. I found myself reading a lot more material, documents and literature.
Studying the dynamics of memories over time: Comparing interviews conducted during different periods can provide valuable insights into the evolution of memories over time.
Exploring the exceptions: investigating more on individuals who are less recognized in historical archives.
Exploring the possible bias in the questions: In order to gain a more comprehensive understanding of our results, it would be beneficial to examine the formulation and content of the questions.
Team: Davide Romano, Cindy Tang, Junzhe Tang
Author: Davide Romano